I’m busy with work these days, so I think I’m writing in two weeks. (Actually, I couldn’t write it because I was tired. LOL) Today I’m going to share a tip that I used a lot on bugbounty. 요즘 일로 인해 바빠서 거의 2주만에 글을 쓰는 것 같습니다. (사실 피곤해서 못썼어요..ㅋㅋ) 오늘은 내가 버그바운티에서 자주 사용하던 팁 하나를 공유하려고 합니다.
This is an endpoint analysis using waybackmachine from archive.org. archive.org 의 waybackmachine을 이용한 endpoint 분석 방법입니다 :)

What is waybackmachine?
Waybackmachine is a site where you can view changes in web pages year by year based on records collected from the web. This allows you to see the pages and changes that existed at the end of each day. waybackmachine은 웹에서 수집된 기록을 토대로 년도별로 웹 페이지의 변화를 볼 수 있는 사이트입니다. 이를 통해서 각 서비스들의 옜날 존재했던 페이지들이나 변화를 볼 수 있죠.
https://web.archive.org/web/sitemap/https://www.hahwul.com
 |
|---|
| 도메인을 바꾼 2016년 이후 데이터는 모두 누적되어 있네요 :) |
It’s usually used for human curiosity, but it’s a slightly different tool for collecting information from a bugbounty perspective. 보통은 사람의 호기심으로 사용하겠지만, 버그바운티를 하는 입장에선 약간 다른 정보 수집 도구가 됩니다.
Recon with waybackmachine(for bugbounty)
The important function we need to see is sitemap. 우리가 중요하게 봐야할 기능은 sitemap 입니다.
waybackmachine => input target site => sitemap
It provides visualization of the crawling data on the site, and shows changes in the year.
For example, let’s look at hackerone.com.
여기에는 해당 사이트의 크롤링 데이터를 시각화해서 보여주게 되어있으며, 년도별로 변화를 알 수 있습니다. 예를들어… hackerone.com을 보겠습니다.

By default, a list of pages exists inside a circular graph, and the more you go outside, the more detailed the page is. It depends on the service, but sometimes the old pages are alive because of compatibility or a person’s mistake. Such pages are old and can be security-sensitive, making them a good prey from hunters. 기본적으로 원형 그래프 내부에는 페이지의 리스트가 존재하며, 내부에서 바깥으로 나갈수록 디테일한 페이지입니다. 서비스에 따라 다르겠지만, 호환성이나 담당자의 실수로 인해서 구형 페이지가 살아있는 경우가 있습니다. 그러한 페이지는 오래되었고, 보안적으로 취약할 수 있어 좋은 먹잇감이 됩니다.
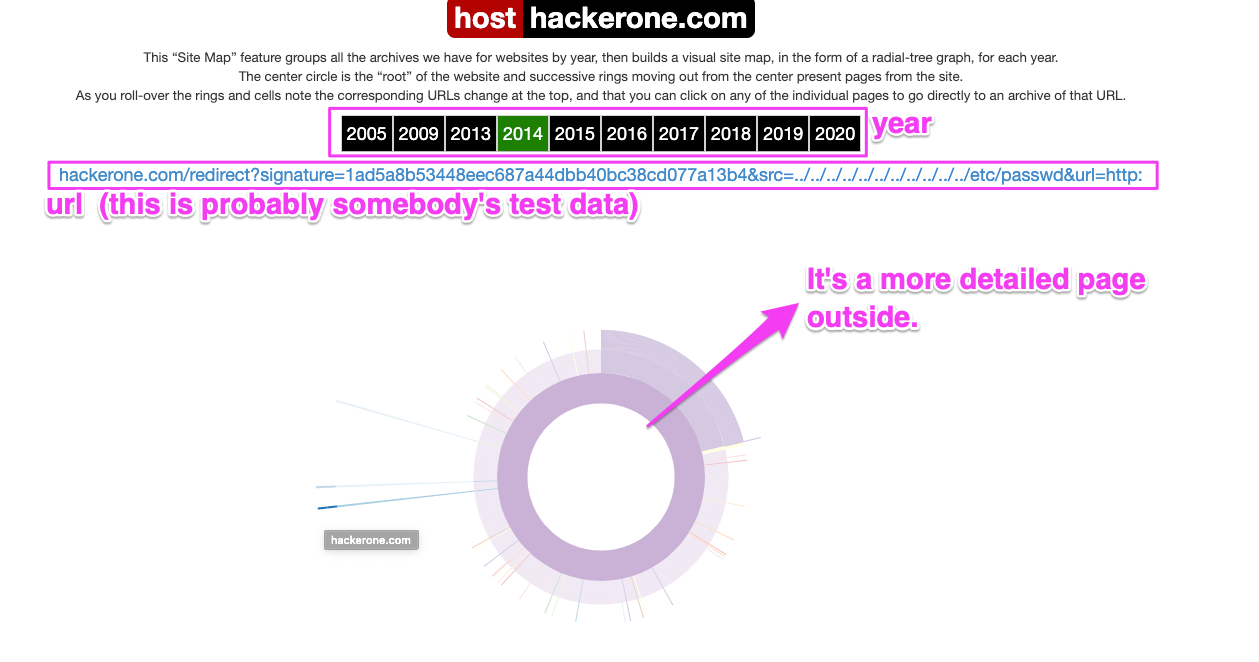
How to embed and use on your page
waybackmachine url is so simple
https://web.archive.org/web/sitemap/https://hackerone.com
https://web.archive.org/web/[function | e.g sitemap]]/{url}
<iframe style="width:80%;height:600px;" src="https://web.archive.org/web/sitemap/https://hackerone.com"></iframe>
How using Rawdata from waybackmahcine
There’s one more thing you can do. It’s using the API of the waybackmachine, and you can get the original data from the graph at the request below. 활용할 수 있는 방법이 하나 더 있습니다. 바로 waybackmachine의 API를 이용하는건데요, 아래 요청으로 그래프의 원본 데이터를 받아올 수 있습니다.
https://web.archive.org/web/timemap/json?url=hackerone.com/&fl=timestamp:4,original,urlkey&matchType=prefix&filter=statuscode:200&filter=mimetype:text/html&collapse=urlkey&collapse=timestamp:4&limit=100000

Data in response can be parse. and using other tools. it is array! Response 내 데이터는 Array로 파싱해서 사용하면 다른 도구에 쉽게 연동할 수 있습니다.
< Request >
GET /web/timemap/json?url=hackerone.com/&fl=timestamp:4,original,urlkey&matchType=prefix&filter=statuscode:200&filter=mimetype:text/html&collapse=urlkey&collapse=timestamp:4&limit=100000 HTTP/1.1
Host: web.archive.org
....snip..
< Response >
[["timestamp:4","original","urlkey"],
["2005","http://www.hackerone.com:80/","com,hackerone)/"],
["2009","http://www.hackerone.com:80/","com,hackerone)/"],
["2014","https://hackerone.com/","com,hackerone)/"],
["2015","https://hackerone.com/","com,hackerone)/"],
...
Conclusion
별거 아니지만, 잘 활용한다면 생각보다 괜찮은 결과를 얻어낼 수 있습니다! 해피해킹!
 |
|---|
| happy hacking!! |